前几篇文章介绍了urllib库基本使用和爬虫的简单应用,本文介绍如何通过post信息给网站,保存登陆后cookie,并用于请求有
权限的操作。保存cookie需要用到cookiejar类,可以输出cookie信息查看下
1 | import http.cookiejar |
1 通过http.cookiejar.CookieJar()创建一个cookiejar对象,用来保存上网留下的cookie。
2 为了处理cookie,需要创建cookie处理器,通过urllib.request.HTTPCookieProcessor(cookie)根据cookie
创建cookie处理器。
3 接下来根据cookie处理器,建立opener, urllib.request.build_opener(handler)创建opener
4 通过openr访问cookie中的数据
可以保存cookie,用于以后访问有权限的网页。下面将cookie写入文件
1 | #定义文件名 |
1 传入文件名,调用http.cookiejar.MozillaCookieJar创建cookie,
cookie和文件名绑定了。
2 根据cookie创建处理器, request.HTTPCookieProcessor创建handler
3 根据Cookie处理器创建opener
4 用opener访问网站,生成cookie
5 cookie.save保存到filename文件中,ignore_discard表示忽略是否过期,
及时被丢弃也保存。ignore_expires表示文件存在则覆盖写入。
对于保存好的cookie文件,可以提取并访问其他网页。
1 | filename = 'cookie.txt' |
1 用MozillaCookieJar创建cookie
2 调用cookie.load加载文件内容到cookie中
3 根据cookie创建HTTPCookieProcessor
4 根据handler创建opener
5 利用opener打开网页,返回response
下面综合应用上面的知识,用爬虫模拟登陆,然后获取有权限的网页和信息。
通过浏览器审查元素的方式可以查看访问网站的request和response,用fiddler更方便一些,用fidder监控浏览器
数据,然后模拟浏览器发送登录请求。
随便找一个需要登陆的网站
http://www.lesmao.cc/forum.php
找到登陆按钮,点击登陆,查看fiddler监控的数据。
可以在fiddler中看到这个request请求post数据给网站。
通过webform这一选项看到我们投递的消息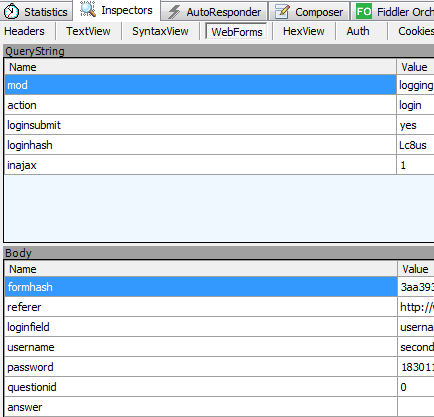
有些网页是需要登陆才能访问的,如
http://www.lesmao.cc/home.php?mod=space&do=notice&view=system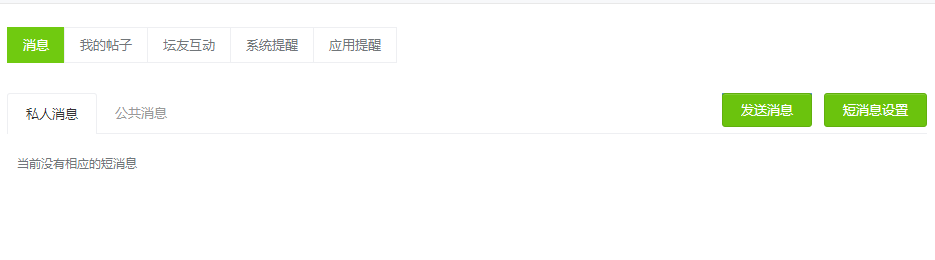
下面先模拟登陆,获取cookie,然后利用cookie访问个人信息网页。
1 | if __name__ == '__main__': |
打印出的html信息和登陆后点击的信息是一致的,所以用cookie登陆并访问其它权限网页成功了。
源码下载地址:
源码下载
我的公众号: