分析ajax请求格式,模拟发送http请求,从而获取网页代码,进而分析取出需要的数据和图片。这里分析ajax请求,获取cosplay美女图片。
登陆今日头条,点击搜索,输入cosplay
下面查看浏览器F12,点击XHR,这里能截取ajax请求,由于已经请求过该页面,所以点击F5,刷新,如下图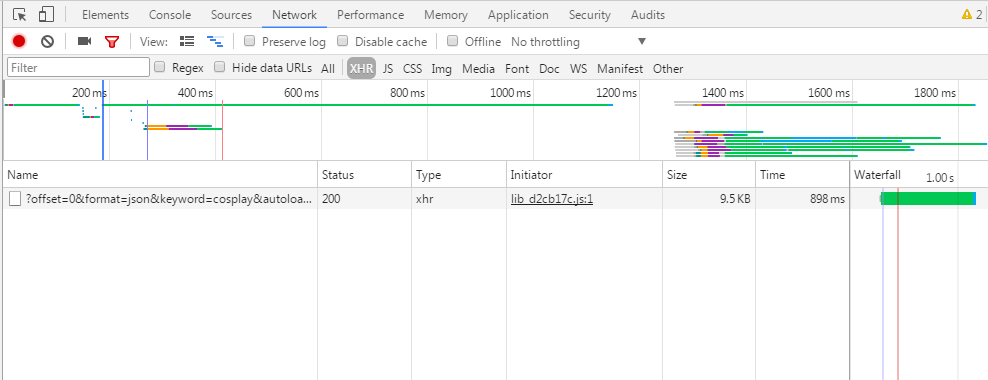
下面我们点击name下的链接,查看headers看到请求信息
可以看到请求的url为
https://www.toutiao.com/search_content/?offset=0&format=json&keyword=cosplay&autoload=true&count=20&cur_tab=1&from=search_tab&pd=synthesis
offset为0,表示当前页面的偏移量,我试着向下滑动页面,name下加载出很多连接,offset每次递增20,keyword为cosplay,是我们搜索的关键词,count表示图集的数量,其他的都不变。
所以我们可以构造一个http请求,包含上面的格式。接下来看看preview的内容
data就是页面加载出来的图片文章列表
点击其中一个data,查看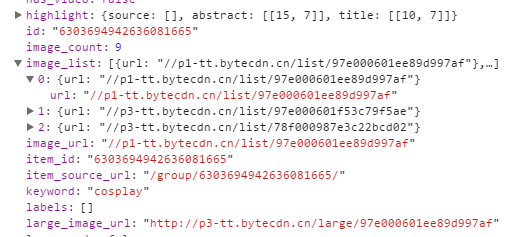
可以看得出图片列表和large图片相差的就是list和large的区别,如
“http://p1-tt.bytecdn.cn/list/97e000601ee89d997af"为缩略图
“http://p1-tt.bytecdn.cn/large/97e000601ee89d997af"为大图
所以只需将list替换为larg即可。之后发送http请求,获取对应的图片即可。下面为完整代码
1 | import requests |
更多源码下载;
https://github.com/secondtonone1/python-/tree/master/pythoncookie
个人博客
https://www.limerence2017.com
谢谢关注我的公总号: