抓取准备
今天是10月24日,祝所有程序员节日快乐。今天打算写个爬虫抓取3DMGAME论坛美女cosplay壁纸。
论坛首页网址为https://www.3dmgame.com/tu_53_1/
我们点击其中一个图集,然后网页跳转,看下源码
1 | <div class="dg-wrapper"> |
网址是静态的,我们直接提取其中的图片链接再下载即可。
抓取网页采用的是python的requests库,直接发送http请求即可。收到回包后,通过BeautifulSoup提炼其中图片地址再次下载即可。
另外我们的界面用的是python自带的Tinker编写的。
代码实现
实现线程装饰器
1 | def thread_run(func): |
封装了一个装饰器,启动线程并调用传入的函数。
我们实现了DownloadFrame类
类里实现如下方法
1 | def prepare(self, downloadlinks): |
prpare函数实现了请求指定网页,并用BeautifulSoup处理回包的功能。
1 |
|
download传给了我们之前封装的装饰器thread_fun, download实现了下载指定图片的功能。
效果展示
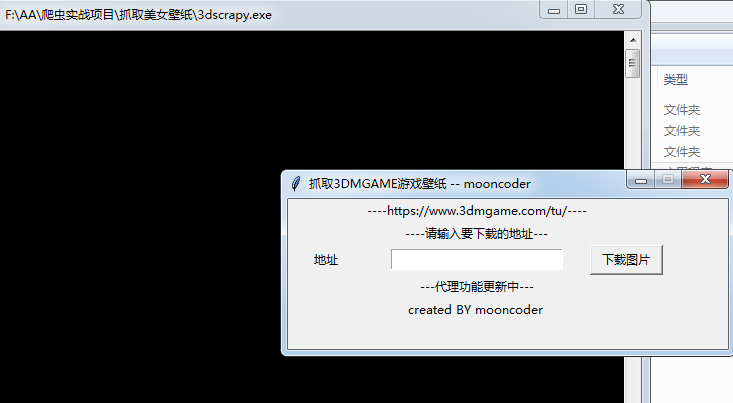
下载图片
感谢关注我的公众号