字节序的问题
在计算机网络中,由于不同的计算机使用的 CPU 架构和字节顺序可能不同,因此在传输数据时需要对数据的字节序进行统一,以保证数据能够正常传输和解析。这就是网络字节序的作用。
具体来说,计算机内部存储数据的方式有两种:大端序(Big-Endian)和小端序(Little-Endian)。在大端序中,高位字节存储在低地址处,而低位字节存储在高地址处;在小端序中,高位字节存储在高地址处,而低位字节存储在低地址处。
在网络通信过程中,通常使用的是大端序。这是因为早期的网络硬件大多采用了 Motorola 处理器,而 Motorola 处理器使用的是大端序。此外,大多数网络协议规定了网络字节序必须为大端序。
因此,在进行网络编程时,需要将主机字节序转换为网络字节序,也就是将数据从本地字节序转换为大端序。可以使用诸如 htonl、htons、ntohl 和 ntohs 等函数来实现字节序转换操作。
综上所述,网络字节序的主要作用是统一不同计算机间的数据表示方式,以保证数据在网络中的正确传输和解析。
如何区分本机字节序
如何区分本机字节序,可以通过判断低地址存储的数据是否为低字节数据,如果是则为小端,否则为大端,下面写一段代码讲述这个逻辑
1 |
|
在上述代码中,使用了一个 is_big_endian() 函数来判断当前系统的字节序是否为大端序。该函数通过创建一个整型变量 num,并将其最低位设置为 1,然后通过指针强制转换成字符指针,判断第一个字节是否为 1 来判断当前系统的字节序。
在 main 函数中,定义了一个整型变量 num,并将其初始化为 0x12345678。接着,使用 char* 类型的指针 p 来指向 num 的地址。然后,通过判断当前系统的字节序来输出 num 的字节序。
如果当前系统为大端序,则按照原始顺序输出各个字节;如果当前系统为小端序,则需要逆序输出各个字节。
例如,如果当前系统为大端序,则输出结果为:
1 | 原始数据:12345678 |
如果当前系统为小端序,则输出结果为:
1 | 原始数据:12345678 |
以上是 C++ 中实现大端字节序和小端字节序的示例。画个图表示大端和小端字节序区别。
大端模式

小端模式
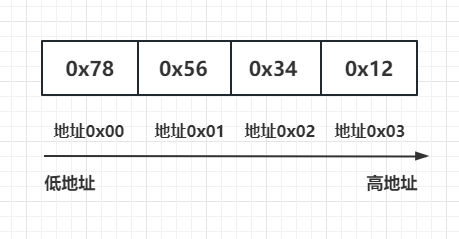
服务器使用网络字节序
为保证字节序一致性,网络传输使用网络字节序,也就是大端模式。
在 boost::asio 库中,可以使用 boost::asio::detail::socket_ops::host_to_network_long() 和 boost::asio::detail::socket_ops::host_to_network_short() 函数将主机字节序转换为网络字节序。具体方法如下:
1 |
|
上述代码中,使用了 boost::asio::detail::socket_ops::host_to_network_long() 和 boost::asio::detail::socket_ops::host_to_network_short() 函数将主机字节序转换为网络字节序。
host_to_network_long() 函数将一个 32 位无符号整数从主机字节序转换为网络字节序,返回转换后的结果。host_to_network_short() 函数将一个 16 位无符号整数从主机字节序转换为网络字节序,返回转换后的结果。
在上述代码中,分别将 32 位和 16 位的主机字节序数值转换为网络字节序,并输出转换结果。需要注意的是,在使用这些函数时,应该确保输入参数和返回结果都是无符号整数类型,否则可能会出现错误。
同样的道理,我们只需要在服务器发送数据时,将数据长度转化为网络字节序,在接收数据时,将长度转为本机字节序。
在服务器的HandleRead函数里,添加对data_len的转换,将网络字节转为本地字节序
1 | short data_len = 0; |
在服务器的发送数据时会构造消息节点,构造消息节点时,将发送长度由本地字节序转化为网络字节序
1 | MsgNode(char * msg, short max_len):_total_len(max_len + HEAD_LENGTH),_cur_len(0){ |
客户端也遵循同样的处理。
消息队列控制
发送时我们会将发送的消息放入队列里以保证发送的时序性,每个session都有一个发送队列,因为有的时候发送的频率过高会导致队列增大,所以要对队列的大小做限制,当队列大于指定数量的长度时,就丢弃要发送的数据包,以保证消息的快速收发。
1 | void CSession::Send(char* msg, int max_length) { |
总结
本文介绍了如何使用网络字节序以及为什么使用网络字节序作为网络传输,且为发送队列设置了阈值保证发送数据的高效性。
源码链接