简介
今天给大家介绍asio多线程模式的第二种,之前我们介绍了IOServicePool的方式,一个IOServicePool开启n个线程和n个iocontext,每个线程内独立运行iocontext, 各个iocontext监听各自绑定的socket是否就绪,如果就绪就在各自线程里触发回调函数。为避免线程安全问题,我们将网络数据封装为逻辑包投递给逻辑系统,逻辑系统有一个单独线程处理,这样将网络IO和逻辑处理解耦合,极大的提高了服务器IO层面的吞吐率。这一次介绍的另一种多线程模式IOThreadPool,我们只初始化一个iocontext用来监听服务器的读写事件,包括新连接到来的监听也用这个iocontext。只是我们让iocontext.run在多个线程中调用,这样回调函数就会被不同的线程触发,从这个角度看回调函数被并发调用了。
结构图
线程池模式的多线程模型调度结构图,如下

先实现IOThreadPool
1 |
|
AsioThreadPool继承了Singleton<AsioThreadPool>,实现了一个函数GetIOService获取iocontext
接下来我们看看具体实现
1 |
|
构造函数中实现了一个线程池,线程池里每个线程都会运行_service.run函数,_service.run函数内部就是从iocp或者epoll获取就绪描述符和绑定的回调函数,进而调用回调函数,因为回调函数是在不同的线程里调用的,所以会存在不同的线程调用同一个socket的回调函数的情况。_service.run 内部在Linux环境下调用的是epoll_wait返回所有就绪的描述符列表,在windows上会循环调用GetQueuedCompletionStatus函数返回就绪的描述符,二者原理类似,进而通过描述符找到对应的注册的回调函数,然后调用回调函数。
比如iocp的流程是这样的
1 | IOCP的使用主要分为以下几步: |
epoll的流程是这样的
1 | 1 调用epoll_creat在内核中创建一张epoll表 |
隐患
IOThreadPool模式有一个隐患,同一个socket的就绪后,触发的回调函数可能在不同的线程里,比如第一次是在线程1,第二次是在线程3,如果这两次触发间隔时间不大,那么很可能出现不同线程并发访问数据的情况,比如在处理读事件时,第一次回调触发后我们从socket的接收缓冲区读数据出来,第二次回调触发,还是从socket的接收缓冲区读数据,就会造成两个线程同时从socket中读数据的情况,会造成数据混乱。
利用strand改进
对于多线程触发回调函数的情况,我们可以利用asio提供的串行类strand封装一下,这样就可以被串行调用了,其基本原理就是在线程各自调用函数时取消了直接调用的方式,而是利用一个strand类型的对象将要调用的函数投递到strand管理的队列中,再由一个统一的线程调用回调函数,调用是串行的,解决了线程并发带来的安全问题。

图中当socket就绪后并不是由多个线程调用每个socket注册的回调函数,而是将回调函数投递给strand管理的队列,再由strand统一调度派发。
为了让回调函数被派发到strand的队列,我们只需要在注册回调函数时加一层strand的包装即可。
在CSession类中添加一个成员变量
1 | strand<io_context::executor_type> _strand; |
CSession的构造函数
1 | CSession::CSession(boost::asio::io_context& io_context, CServer* server): |
可以看到_strand的初始化是放在初始化列表里,利用io_context.get_executor()返回的执行器构造strand。
因为在asio中无论iocontext还是strand,底层都是通过executor调度的,我们将他理解为调度器就可以了,如果多个iocontext和strand的调度器是一个,那他们的消息派发统一由这个调度器执行。
我们利用iocontext的调度器构造strand,这样他们统一由一个调度器管理。在绑定回调函数的调度器时,我们选择strand绑定即可。
比如我们在Start函数里添加绑定 ,将回调函数的调用者绑定为_strand
1 | void CSession::Start(){ |
同样的道理,在所有收发的地方,都将调度器绑定为_strand, 比如发送部分我们需要修改为如下
1 | auto& msgnode = _send_que.front(); |
回调函数的处理部分也做对应的修改即可。
性能对比
为了比较两种服务器多线程模式的性能,我们还是利用之前测试的客户端,客户端每隔10ms建立一个连接,总共建立100个连接,每个连接收发500次,总计10万个数据包,测试一下性能。
客户端测试代码如下
1 |
|
我们先启动之前实现的AsioIOServicePool多线程模式的服务器测试,10万个数据包收发完成总计46秒
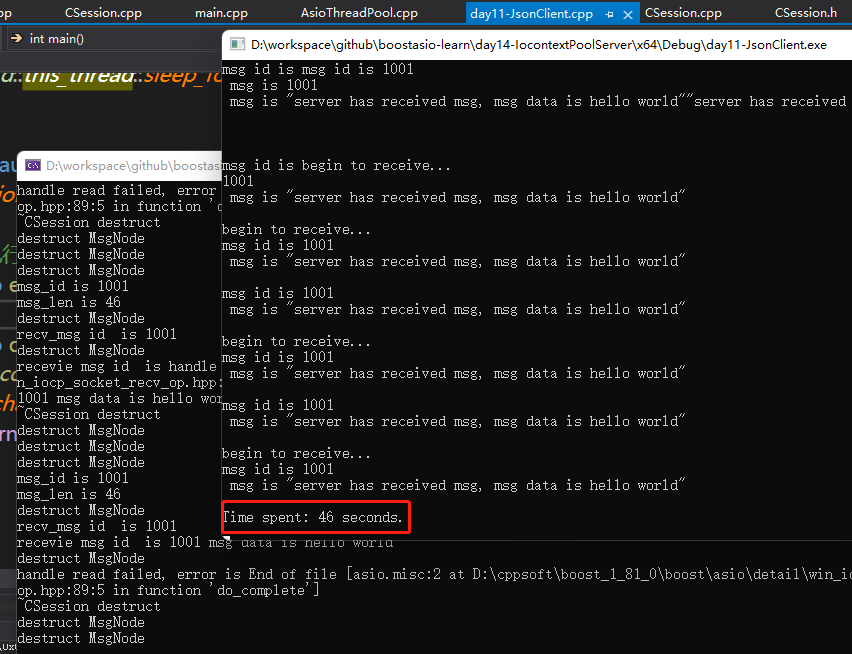
接下来我们启动ASIOThreadPool多线程模式的服务器测试,10万个数据包收发完成总计53秒

可以看出今天实现的多线程模式较之前的IOServicePool版本慢了7秒
取舍
实际的生产和开发中,我们尽可能利用C++特性,使用多核的优势,将iocontext分布在不同的线程中效率更可取一点,但也要防止线程过多导致cpu切换带来的时间片开销,所以尽量让开辟的线程数小于或等于cpu的核数,从而利用多核优势。
视频连接https://space.bilibili.com/271469206/channel/collectiondetail?sid=313101