按数量切分
对于大量处理的数据,可以按照任务数量区分,简单来说如果我们要处理n个任务,总计有m个线程,那么我们可以简单的规划每个线程处理n/m个任务。
如下图
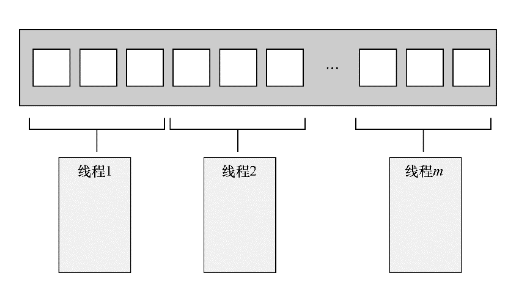
这种方式用来划分大量相同任务时可以采用,但是有些逻辑并不是完全可以靠数量划分的,比如递归逻辑。
递归划分
前文我们提及了快速排序的并行实现,包括利用async和线程池的方式。
快速排序算法含有两大基本步骤:
选定一个元素为比较的基准元素;
将数据集按大小划分为前后两部分,重新构成新序列,再针对这两个部分递归排序。
数据划分无法从一开始就并行化,因为数据只有经过处理后,我们才清楚它会归入哪个部分。
若我们要并行化这个算法,就需要利用递归操作的固有性质。
每层递归均会涉及更多的quick_sort()函数调用,因为我们需对基准元素前后两部分都进行排序。
由于这些递归调用所访问的数据集互不相关,因此它们完全独立,正好吻合并发程序的首选执行方式。
下图展示了以递归方式划分数据。
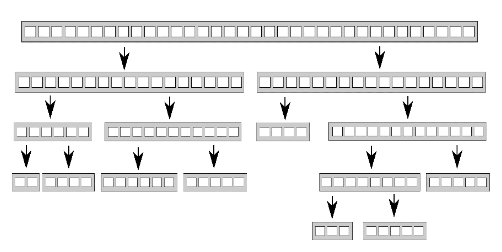
在早期我们实现并行递归的快速排序,那段代码每深入一层递归,都借std::async()生成新的异步任务处理前半部分数据,而后部分则继续用本线程计算后半部分数据。
我们通过std::async()让C++线程库自主决定,是另起新线程执行新任务,还是在原线程上同步运行。
这点相当重要:假设排序操作的数据集非常庞大,若每次递归都生成新线程,则势必令线程数目激增。
我们将通过后文的性能分析了解到,太多线程反而可能令应用程序变慢。
如果数据集着实庞大,还有可能消耗殆尽全部线程。按上述递归方式来切分数据是不错的思路,但需约束线程数目的增长,不可任其数目无限膨胀。
此例比较简单,std::async()足以应付,但它不是唯一选择。
后来我们觉得开辟过多的线程并不合适,采用了线程池。
并发编程的作者提出的另一种做法是,根据std::hardware_concurrency()函数的返回值设定线程的数目,实现了accumulate()的并行版本。
接着,我们采用之前实现的线程安全的栈容器,将尚未排序的数据段压入其中,而不是启动新线程以执行递归调用。
若某线程无所事事,或因全部数据段均已处理妥当,或因它正等着另一数据段完成排序,若是后者,该线程即从栈容器取出所等的数据段自行排序。
1 |
|
我们实现一个函数调用上面的封装快速排序
1 | template<typename T> |
本例中,parallel_quick_sort()函数(19处)把绝大部分功能委托给sorter类(1处),后者通过栈容器管理待排序的数据段(2处),并集中管控多个线程以并发执行任务(3处),从而以便捷的操作方式给出了代码实现。
本例中,主要工作由成员函数do_sort()负责(9处),它借标准库的std::partition()函数完成数据分段(10处)。
do_sort()将新划分出来的数据段压入栈容器(11处),但没有为每个数据段都专门生成新线程,而仅当仍存在空闲的处理器时(12处)才生成新线程。
因为划分出的前半部分数据可能会由别的线程处理,所以我们需要等待它完成排序而进入就绪状态(13处)。
如果当前线程是整个程序中仅有的线程,或者其他线程都正忙于别的任务,那么这一等待行为则需妥善处理,在当前线程的等待期间,我们让它试着从栈容器取出数据进行处理(14处)。
try_sort_chunk()先从栈容器弹出一段数据(7处)并对其进行排序(8处),再把结果存入附属该段的promise中(15处),使之准备就绪,以待提取。
向栈容器压入数据段与取出相关结果相互对应,两项操作均由同一个线程先后执行(11和12处)。
只要标志end_of_data没有成立(16处),各线程便反复循环,尝试对栈内数据段进行排序17。
每个线程在两次检测标志之间进行让步(18处),好让别的线程有机会向栈容器添加数据段。这段代码由sorter类的析构函数汇合各个线程(4处)。
do_sort()将在全部数据段都完成排序后返回(即便许多工作线程仍在运行),主线程进而从parallel_quick_sort()的调用返回20,并销毁sorter对象。其析构函数将设置标志end_of_data成立(5处),然后等待全部线程结束(6处)。标志的成立使得线程函数内的循环终止(16处)。
按照工作类别划分任务
单线程应用程序照样需要同时运行多个任务,而某些程序即便正忙于手头的任务,也需随时处理外部输入的事件(譬如用户按键或网络数据包传入)。这些情形都与单一功能的设计原则矛盾,必须妥善处理。若我们按照单线程思维手动编写代码,那最后很可能混成“大杂烩”:先执行一下任务甲,再执行一下任务乙,接着检测按键事件,然后检查传入的网络数据包,又回头继续执行任务甲,如此反复循环。这就要求任务甲保存状态,好让控制流程按周期返回主循环,结果令相关的代码复杂化。如果向循环加入太多任务,处理速度便可能严重放缓,让用户感觉按键的响应时间过长。相信读者肯定见过这种操作方式的极端表现:我们让某个应用程序处理一些任务,其用户界面却陷入僵滞,到任务完成后才恢复。
只要把每个任务都放在独立的线程上运行,操作系统便会替我们“包办”切换动作。因此,任务甲的代码可专注于执行任务,我们无须再考虑保存状态和返回主循环,也不必纠结间隔多久就得这样操作。
假定每项任务都相互独立,且各线程无须彼此通信,那么该构想即可轻而易举地实现。可惜往往事与愿违。即便经过良好的设计,后台任务也常常按用户要求执行操作,它们需在完成时通过某种方式更新界面,好让用户知晓。反之,若用户想取消任务,就要通过界面线程向后台任务发送消息,告知它停止。
所以各个任务线程中要提供互相通知的接口,这种思想和Actor模式不谋而合。
当然我们划分任务给不同的线程也要注意精细程度,比如两个线程要做的功能中某个环节是一个共有的功能,那么我们需要将这个功能整合到一个单线程上。我们可以理解在一些高并发的设计中,即便某些模块是高并发,但是耦合度很高的逻辑处理还是采用单线程方式,我们之前设计网络i服务器是逻辑处理也是单线程,但是我们可以根据功能做区分再分化为不同的线程,这就类似于Actor设计模式了。
假设有这样一个情形,我们实现一个系统控制机器中各部件的运动,A部件运动结束后通知B部件运动,B部件结束后通知C部件继续运动等,C运动结束后再通知A部件继续运动。
按照任务划分的模式,A,B,C分别运行在不同的线程中处理不同的任务,而任务又要以流水线A->B->C的方式运作。
我们可以这样抽象出一个Actor类,它包含消息的投递,消息的处理,以及消息队列的管理,并且它是一个单例类,全局唯一。
先实现这个基本的模板单例类, 这期间会用到CRTP技术,CRTP:一个继承 以自己为模板参数的模板类 的类。
CRTP 奇特递归模板技术, Curiously recurring template pattern。
模板单例类实现如下
1 |
|
模板单例类包含了原子变量_bstop控制线程是否停止
包含了_que用来存储要处理的信息,这是一个线程安全的队列。
_thread是要处理任务的线程。
线程安全队列我们之前有实现过,但是还需要稍微改进下以满足接受外部停止的通知。
我们给ThreadSafeQue添加一个原子变量_bstop表示线程停止的标记
在需要停止等待的时候我们调用如下通知函数
1 | void NotifyStop() { |
等待消息的函数需要补充根据停止条件去返回的逻辑,目的为防止线程被一直挂起
1 | std::unique_lock<std::mutex> wait_for_data() |
修改wait_pop_head,根据停止条件返回空指针
1 | std::unique_ptr<node> wait_pop_head() |
等待返回数据的逻辑也稍作修改,因为有可能是接收到停止信号后等待返回,所以此时返回空指针即可
1 | std::shared_ptr<T> WaitAndPop() // <------3 |
比如我们要实现一个ClassA 处理A类任务,可以这么做
1 |
|
我们利用CRTP模式让ClassA继承了以ClassA为类型的模板,然后在DealMsg函数内部调用了 ClassB的投递消息,将任务B交给另一个线程处理。
关于ClassB的实现方式和ClassA类似,然后我们在ClassB的DealMsg中调用ClassC的PostMsg将消息投递给C的线程处理。
达到的效果就是
A->B->C
我们在主函数调用
1 |
|
程序输出如下
1 | class A deal msg is llfc |
可以看到处理的顺序是A->B->C,并且每个类都有析构和函数回收,说明我们的程序不存在内存泄漏。
这里要提示读者一个问题,如果A给B投递消息,而B又要给A投递消息,那么如果在A的头文件包含B的头文件,而B的头文件包含A的头文件势必会造成互引用问题,那么最好的解决方式就是在A和B的头文件中分别声明对方,在cpp文件中再包含即可。
上面的例子通过模板和继承的方式实现了类似Actor的收发消息的功能。
总结
本文介绍了线程划分任务的三种方式
1 按照任务的数量划分
2 递归划分
3 按照任务的种类划分
源码链接:
https://gitee.com/secondtonone1/boostasio-learn/tree/master/concurrent/day20-Actor
视频链接:
https://space.bilibili.com/271469206/channel/collectiondetail?sid=1623290