多维数组
更多资料可查阅官方博客,官方博客地址:https://llfc.club/
严格来说,C++语言中没有多维数组,通常所说的多维数组其实是数组的数组。谨记这一点,对今后理解和使用多维数组大有益处。
当一个数组的元素仍然是数组时,通常使用两个维度来定义它:一个维度表示数组本身大小,另外一个维度表示其元素(也是数组)大小:
1 | // 大小为3的数组,每个元素是大小为4的数组 |
按照由内而外的顺序阅读此类定义有助于更好地理解其真实含义。
在第一条语句中,我们定义的名字是ia,显然ia是一个含有3个元素的数组。
接着观察右边发现,ia的元素也有自己的维度,所以ia的元素本身又都是含有4个元素的数组。
再观察左边知道,真正存储的元素是整数。因此最后可以明确第一条语句的含义:它定义了一个大小为3的数组,该数组的每个元素都是含有4个整数的数组。
上面的代码可以理解为下面的形式
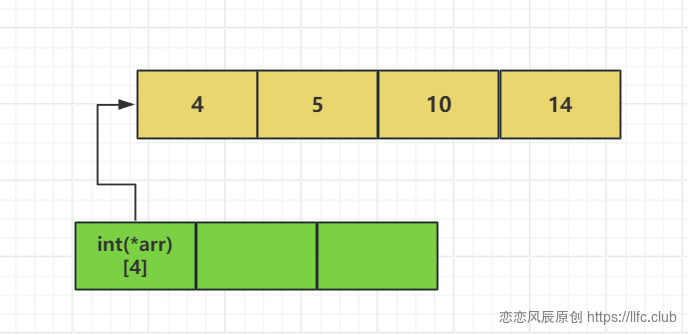
也可以初始化为
1 | // 这些数组的元素是含有30个整数的数组 |
使用同样的方式理解arr的定义。
首先arr是一个大小为10的数组,它的每个元素都是大小为20的数组,这些数组的元素又都是含有30个整数的数组。
实际上,定义数组时对下标运算符的数量并没有限制,因此只要愿意就可以定义这样一个数组:它的元素还是数组,下一级数组的元素还是数组,再下一级数组的元素还是数组,以此类推。对于二维数组来说,常把第一个维度称作行,第二个维度称作列。
多维数组的初始化
允许使用花括号括起来的一组值初始化多维数组,这点和普通的数组一样。下面的初始化形式中,多维数组的每一行分别用花括号括了起来:
1 | //三个元素,每个元素是大小为4的数组 |
其中内层嵌套着的花括号并非必需的,例如下面的初始化语句,形式上更为简洁,完成的功能和上面这段代码完全一样:
1 | int ia[3][4] = {0,1,2,3,4,5,6,7,8,9,10,11}; |
类似于一维数组,在初始化多维数组时也并非所有元素的值都必须包含在初始化列表之内。如果仅仅想初始化每一行的第一个元素,通过如下的语句即可:
1 | //初始化每一行的首元素 |
其他未列出的元素执行默认值初始化,这个过程和一维数组一样。在这种情况下如果再省略掉内层的花括号,结果就大不一样了。
1 | //值初始化第一i行 |
含义发生了变化,它初始化的是第一行的4个元素,其他元素被初始化为0。
多维数组的下标
引用可以使用下标运算符来访问多维数组的元素,此时数组的每个维度对应一个下标运算符。
如果表达式含有的下标运算符数量和数组的维度一样多,该表达式的结果将是给定类型的元素;
反之,如果表达式含有的下标运算符数量比数组的维度小,则表达式的结果将是给定索引处的一个内层数组:
1 | int ia[3][4] = {{1,2,3,4}, |
使用for循环
我们可以使用for循环构建数组
1 | constexpr size_t rowCnt = 3, colCnt=4; |
C++11风格处理多维数组
由于C++11新标准增加了范围for语句,所以前一个程序可以简化为
1 | constexpr size_t rowCnt = 3, colCnt=4; |
输出每一个元素
1 | for(const auto & row: ia){ |
输出
1 | 0 1 2 3 |
指针和多维数组
当程序使用多维数组的名字时,也会自动将其转换成指向数组首元素的指针。
新手雷区
定义指向多维数组的指针时,千万别忘了这个多维数组实际上是数组的数组。
因为多维数组实际上是数组的数组,所以由多维数组名转换得来的指针实际上是指向第一个内层数组的指针:
1 | //大小为3的数组,每个元素是含有4个整数的数组 |
随着C++11新标准的提出,通过使用auto或者decltype就能尽可能地避免在数组前面加上一个指针类型了:
1 | // ia数组 |
使用C++11提供的std::begin也能实现类似的功能
1 | // ia数组 |
类型别名简化多维数组指针
可以使用using 进行类型别名的声明,或者使用typedef声明类型的别名
1 | // ia数组 |
练习题1:矩阵加法
题目描述
编写一个C++程序,输入两个2x3的矩阵,计算它们的和,并输出结果矩阵。
示例代码框架
1 |
|
预期输出(示例)
1 | 请输入第一个2x3矩阵的元素(共6个整数): |
答案
1 |
|
练习题2:矩阵转置
题目描述
编写一个C++程序,输入一个3x3的矩阵,计算其转置矩阵,并输出结果。
示例代码框架
1 |
|
预期输出(示例)
1 | 请输入一个3x3矩阵的元素(共9个整数): |
答案
1 |
|
赞赏
感谢支持