本文介绍如何结合前面讲解的基本知识,采用requests,正则表达式,cookies结合起来,做一次实战,抓取猫眼电影排名信息。
用requests写一个基本的爬虫
排行信息大致如下图
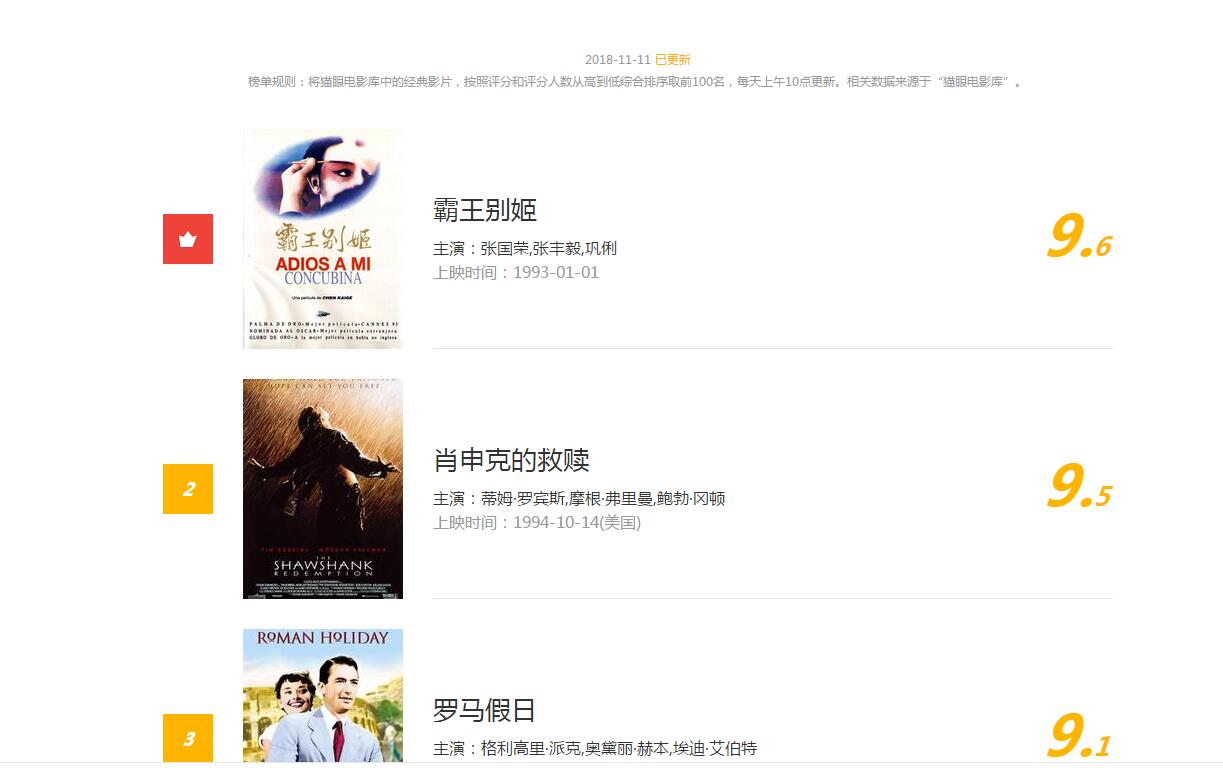
网址链接为http://maoyan.com/board/4?offset=0
我们通过点击查看源文件,可以看到网页信息
每一个电影的html信息都是下边的这种结构
1 | <i class="board-index board-index-3">3</i> |
其实对我们有用的就是 img src(图片地址) title 电影名 star 主演。
所以根据前边介绍过的正则表达式写法,可以推导出正则表达式
1 | compilestr = r'''<dd>.*?<i class="board-index.*?<img data-src="(.*?)@.*?title="(.*?)".*?<p class="star"> |
‘.’表示匹配任意字符,如果正则表达式用re.S模式,.还可以匹配换行符,’‘表示匹配前一个字符0到n个,’?’表示非贪婪匹配,
所以’.?’可以理解为匹配任意字符。接下来写代码打印我们匹配的条目
1 | #-*-coding:utf-8-*- |
运行一下,结果如下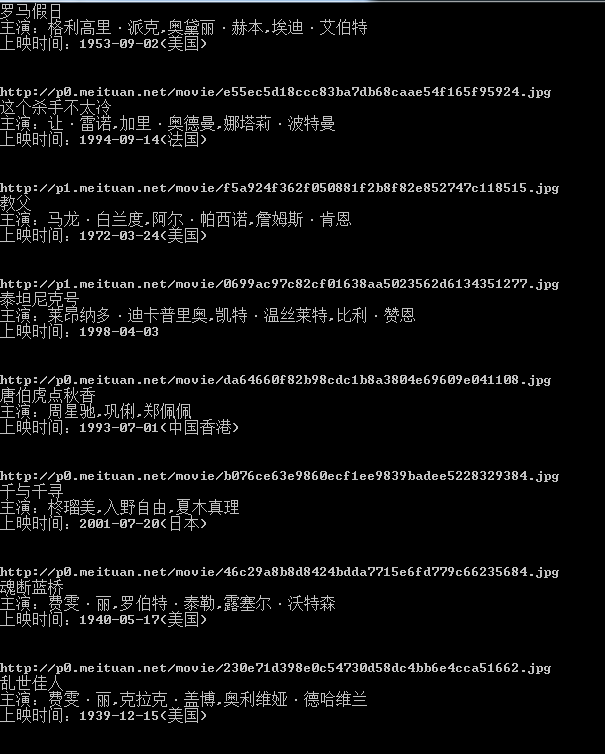
看来我们抓取到数据了,我们只爬取了这一页的信息,接下来我们分析第二页,第三页的规律,点击第二页,网址变为’http://maoyan.com/board/4?offset=10',点击第三页网址变为'http://maoyan.com/board/4?offset=20',所以每一页的offset偏移量为20,这样我们可以计算偏移量达到抓取不同页码的数据,将上一个程序稍作修改,变为可以爬取n页数据的程序
1 | #-*-coding:utf-8-*- |
运行下,效果和之前一样,只是支持了页码的传参了。
下面继续完善下程序,把每个电影的图片抓取并保存下来,这里面用到了创建文件夹,路径拼接,文件保存的基础知识,综合运用如下
1 | #-*-coding:utf-8-*- |
运行一下,可以看到在文件的目录里多了几个文件夹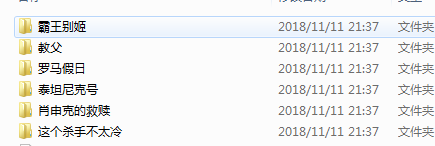
点击一个文件夹,看到里边有我们保存的图片和信息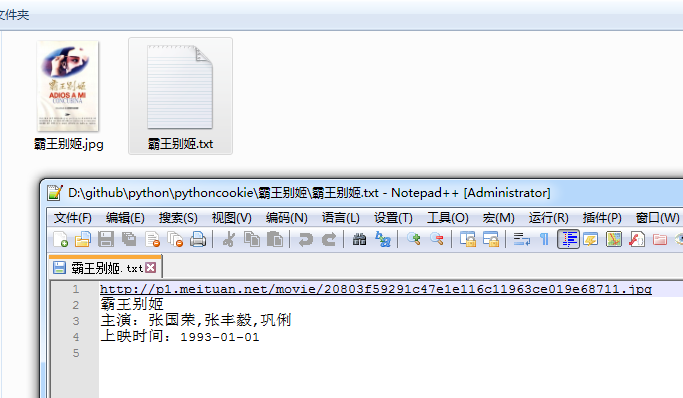
好了,到此为止,正则表达式和requests结合,做的爬虫实战完成。
谢谢关注我的公众号: