BeautifulSoup是python的html解析库,处理html非常方便
BeautifulSoup 安装
pip install beautifulsoup4
BeautifulSoup 配合的解析器
1 | # python标准库 |
python 标准库解析器不需要第三方库,处理效率一般,lxml比较快,需要C语言库支持,html5lib不依赖第三方库,但是效率比较低,容错好。
导入BeautifulSoup并使用
1 | from bs4 import BeautifulSoup |
bs.prettify为格式化输出,效果如下
同样可以用本地的html文本创建,也可以添加解析器lxml
1 | s =BeautifulSoup('test.html','lxml') |
效果是一样的
BeautifulSoup属性选择和处理
处理节点tag
1 | html2 = ''' <li class="bus_postbd item masonry_brick"> |
节点tag 就是li,a,div这类,可以看出通过属性访问,选择出第一个匹配的结果。节点Tag也有名字,通过.name访问。通过.attrs获取节点的属性。
获取节点文本通过.string即可,获取节点的子孙节点的文本可以通过text
1 | print(s2.a.string) |
节点的子孙节点
获取节点的子节点,可以用.contents,也可以用.children, .contents返回列表形式的直接子节点, .contents返回的是一个可迭代对象。
1 | print(s2.div.contents) |
前两个输出一样,后边的分别取第一个节点,以及遍历每一个节点。同样的道理,子孙节点,父节点,祖父节点,兄弟节点都采用这种方式获取
1 | #孙子节点 |
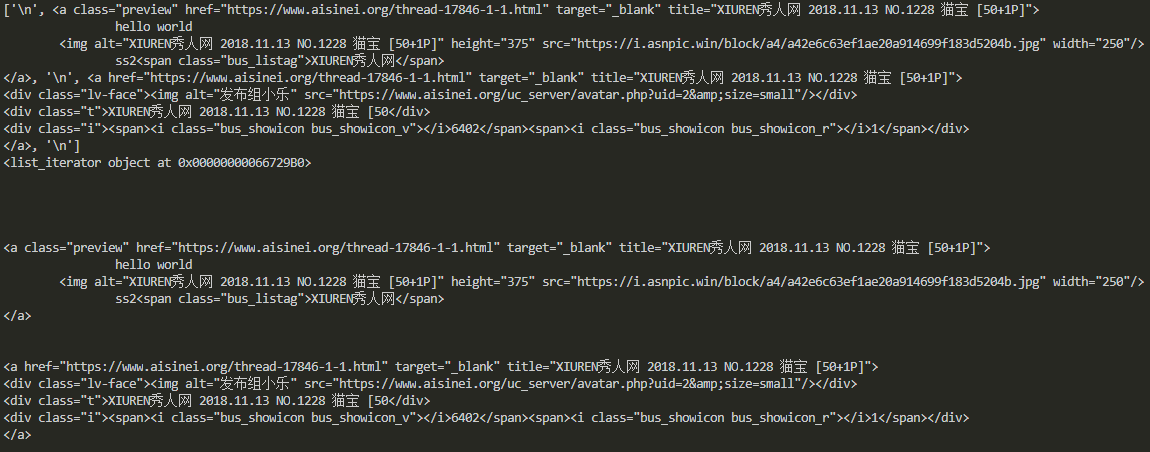
节点的属性获取
1 | print(s2.a["href"]) |
如上两种方式都能获取属性
方法选择
常用的筛选函数有find_all和find,findall返回所有匹配的结果,find返回匹配结果的
1 | print(s2.find('a')) |
可以看出findall传递参数可以是字符串,正则表达式,列表等等,其他的方法类似属性访问一样,有find_parents(),find_next_siblings()等等,用的时候再查吧。
BeautifulSoup 支持CSS选择器
如果你熟悉css选择器的语法,BeautifulSoup同样支持,而且非常便利。
1 | #查找节点为div的数据 |
到目前为止基本的BeautifulSoup已经介绍完,下面实战抓取一段html,并用BeautifulSoup解析提取我们需要的数据,这里解析一段美女图更新首页,提取其中的资源地址。
1 | #-*-coding:utf-8-*- |
抓取并分析出地址如下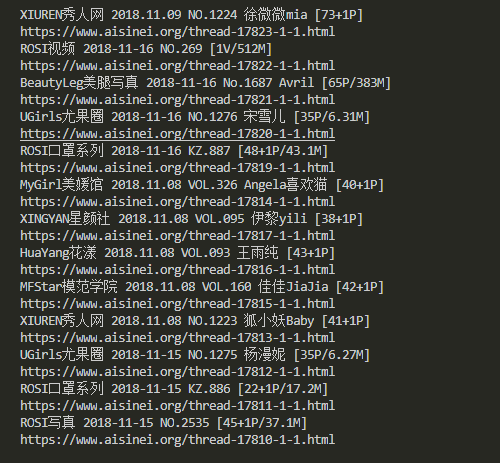
下一篇讲如何利用ajax分析动态网址,实战抓取今日头条的cosplay图片
谢谢关注我的公众号