简介
前文我们通过原子操作实战实现了无锁队列,今天完善一下无锁的原子操作剩余的知识,包括Relaese和Acquire内存序在什么情况下是存在危险的,以及我们可以利用栅栏机制实现同步等等。
线程可见顺序
我们提到过除了memory_order_seq_cst顺序,其他的顺序都不能保证原子变量修改的值在其他多线程中看到的顺序是一致的。
但是可以通过同步机制保证一个线程对原子变量的修改对另一个原子变量可见。通过“Syncronizes With” 的方式达到先行的效果。
但是我们说的先行是指 “A Syncronizes With B ”, 如果A 的结果被B读取,则A 先行于B。
有时候我们线程1对A的store操作采用release内存序,而线程2对B的load采用acquire内存序,并不能保证A 一定比 B先执行。因为两个线程并行执行无法确定先后顺序,我们指的先行不过是说如果B读取了A操作的结果,则称A先行于B。
我们看下面的一段案例
1 |
|
我们写一个函数测试,函数TestAR中初始化x和y为false, 启动4个线程a,b,c,d,分别执行write_x, write_y, read_x_then_y, read_y_then_x.
1 | void TestAR() |
有的读者可能会觉5处的断言不会被触发,他们认为c和d肯定会有一个线程对z执行++操作。他们的思路是这样的。
1 如果c线程执行read_x_then_y没有对z执行加加操作,那么说明c线程读取的x值为true, y值为false。
2 之后d线程读取时,如果保证执行到4处说明y为true,等d线程执行4处代码时x必然为true。
3 他们的理解是如果x先被store为true,y后被store为true,c线程看到y为false时x已经为true了,那么d线程y为true时x也早就为true了,所以z一定会执行加加操作。
上述理解是不正确的,我们提到过即便是releas和acquire顺序也不能保证多个线程看到的一个变量的值是一致的,更不能保证看到的多个变量的值是一致的。
变量x和y的载入操作3和4有可能都读取false值(与宽松次序的情况一样),因此有可能令断言触发错误。变量x和y分别由不同线程写出,所以两个释放操作都不会影响到对方线程。
看下图
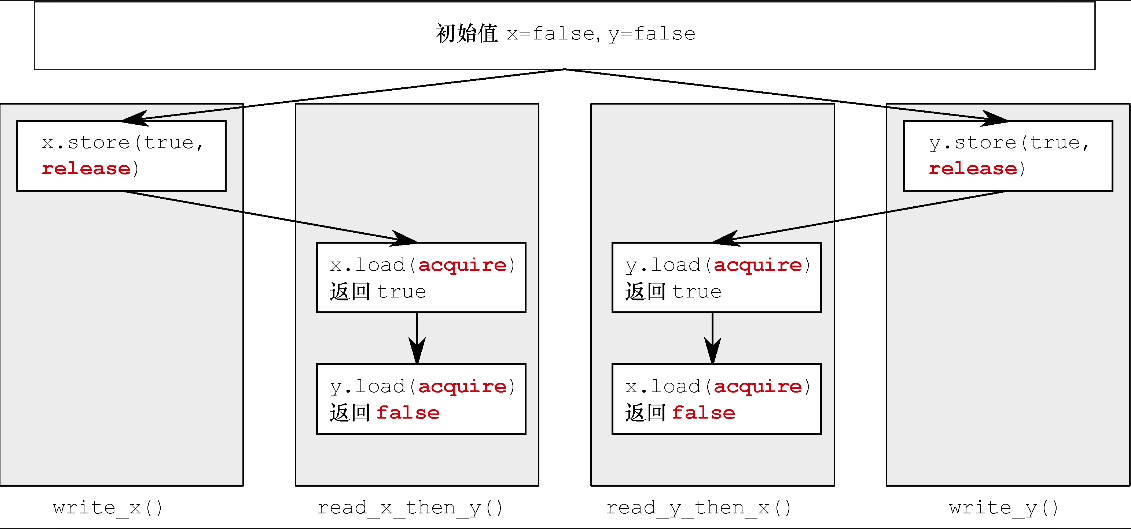
无论x和y的store顺序谁先谁后,线程c和线程d读取的x和y顺序都不一定一致。
从CPU的角度我们可以这么理解
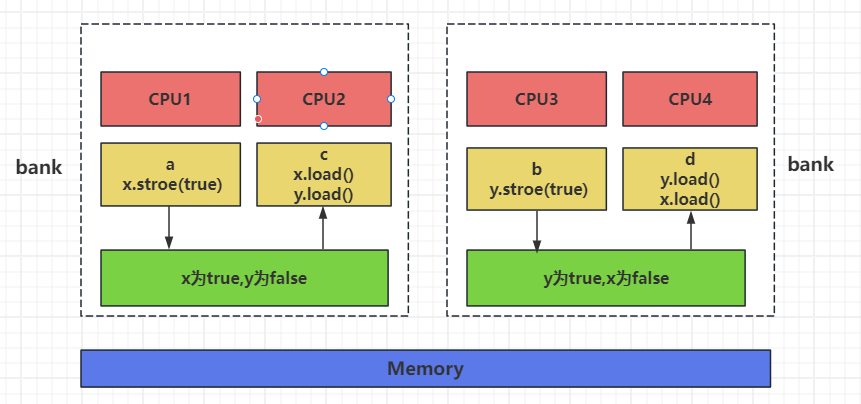
在一个4核CPU结构的主机上,a,b,c,d分别运行在不同的CPU内核上。
a执行x.store(true)先被线程c读取,而此时线程b对y的store还没有被c读取到新的值,所以此时c读取的x为true,y为false。
同样的道理,d可以读取b修改y的最新值,但是没来的及读取x的最新值,那么读取到y为true,x为false。
即使我们采用release和acquire方式也不能保证全局顺序一致。如果一个线程对变量执行release内存序的store操作,另一个线程不一定会马上读取到。这个大家要理解。
栅栏
有时候我们可以通过栅栏保证指令编排顺序。
看下面一段代码
1 |
|
上面的代码我们都采用的是memory_order_relaxed, 所以无法保证a线程将x,y修改后b线程看到的也是先修改x,再修改y的值。b线程可能先看到y被修改为true,x后被修改为true,那么b线程执行到4处时x可能为false导致z不会加加,5处断言会被触发。
那我们之前做法可以解决这个问题
1 | void write_x_then_y3() |
可以通过std::memory_order_release和std::memory_order_acquire形成同步关系。
线程a执行write_x_then_y3,线程b执行read_y_then_x3,如果线程b执行到4处,说明y已经被线程a设置为true。
线程a执行到2,也必然执行了1,因为是memory_order_release的内存顺序,所以线程a能2操作之前的指令在2之前被写入内存。
同样的道理,线程b在3处执行的是memory_order_acquire的内存顺序,所以能保证4不会先于3写入内存,这样我们能知道1一定先行于4.
进而推断出z会加加,所以不会触发assert(z.load() != 0);的断言。
其实我们可以通过栅栏机制保证指令的写入顺序。栅栏的机制和memory_order_release类似。
1 | void write_x_then_y_fence() |
我们写一个函数测试上面的逻辑
1 | void TestFence() |
7处的断言也不会触发。我们可以分析一下,
线程a运行write_x_then_y_fence,线程b运行read_y_then_x_fence.
当线程b执行到5处时说明4已经结束,此时线程a看到y为true,那么线程a必然已经执行完3.
尽管4和3我们采用的是std::memory_order_relaxed顺序,但是通过逻辑关系保证了3的结果同步给4,进而”3 happens-before 4”
因为我们采用了栅栏std::atomic_fence所以,5处能保证6不会先于5写入内存,(memory_order_acquire保证其后的指令不会先于其写入内存)
2处能保证1处的指令先于2写入内存,进而”1 happens-before 6”, 1的结果会同步给 6
所以”atomic_thread_fence”其实和”release-acquire”相似,都是保证memory_order_release之前的指令不会排到其后,memory_order_acquire之后的指令不会排到其之前。
总结
视频链接
https://space.bilibili.com/271469206/channel/collectiondetail?sid=1623290
源码链接
https://gitee.com/secondtonone1/boostasio-learn/tree/master/concurrent/day13-fence